Publications
CARL: Critical Action Focused Reinforcement Learning for Multi-Step Agent
Leyang Shen, Yang Zhang, Chun Kai Ling, Xiaoyan Zhao, Tat-Seng Chua
arXiv preprint arXiv:2512.04949 2025
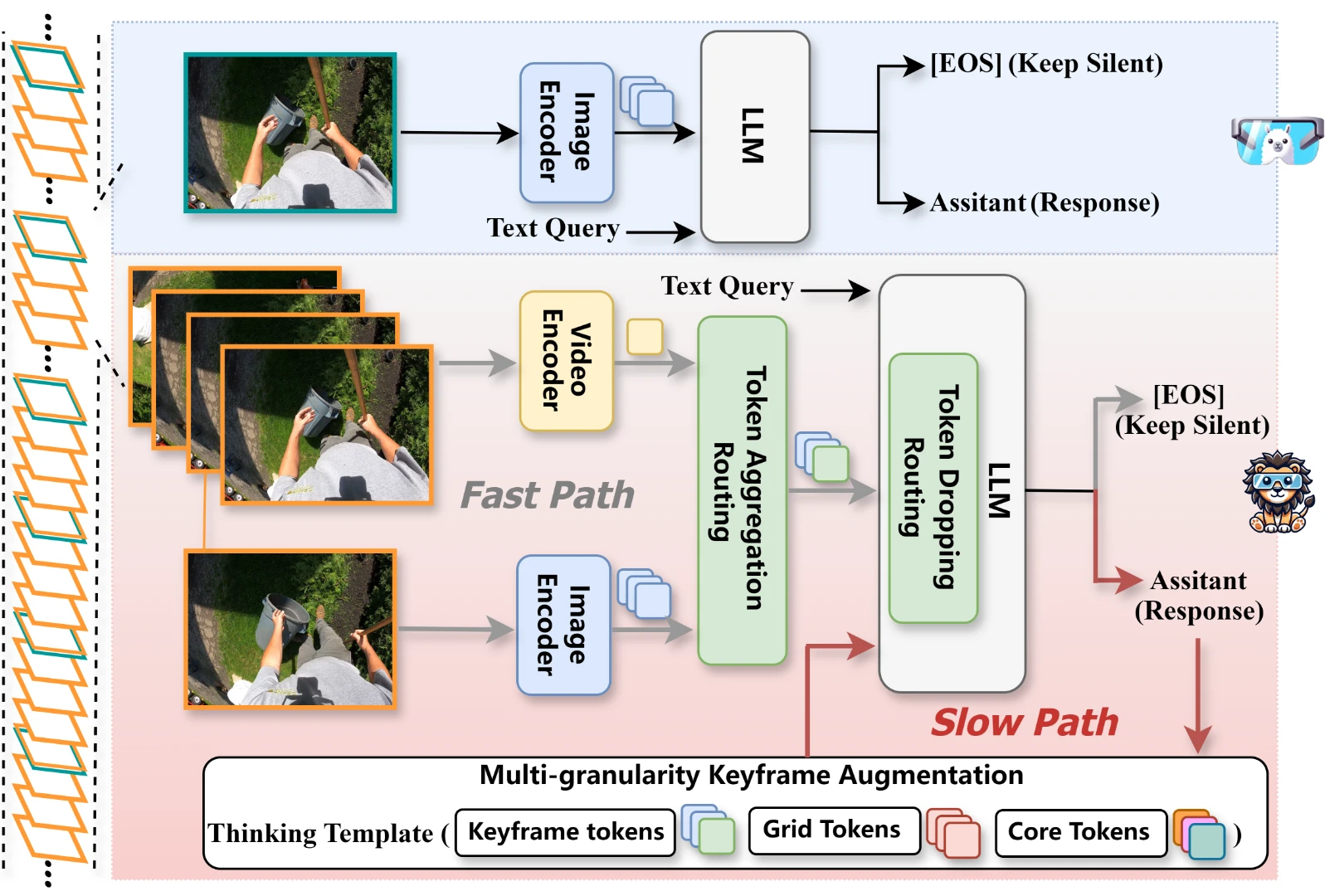
LION-FS: Fast & Slow Video-Language Thinker as Online Video Assistant
Wei Li, Bing Hu, Rui Shao, Leyang Shen, Liqiang Nie
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2025
In this work, we propose “Fast & Slow Video-Language Thinker” as onLIne videO assistaNt, LION-FS, achieving real-time, proactive, temporally accurate, and contextually precise responses.
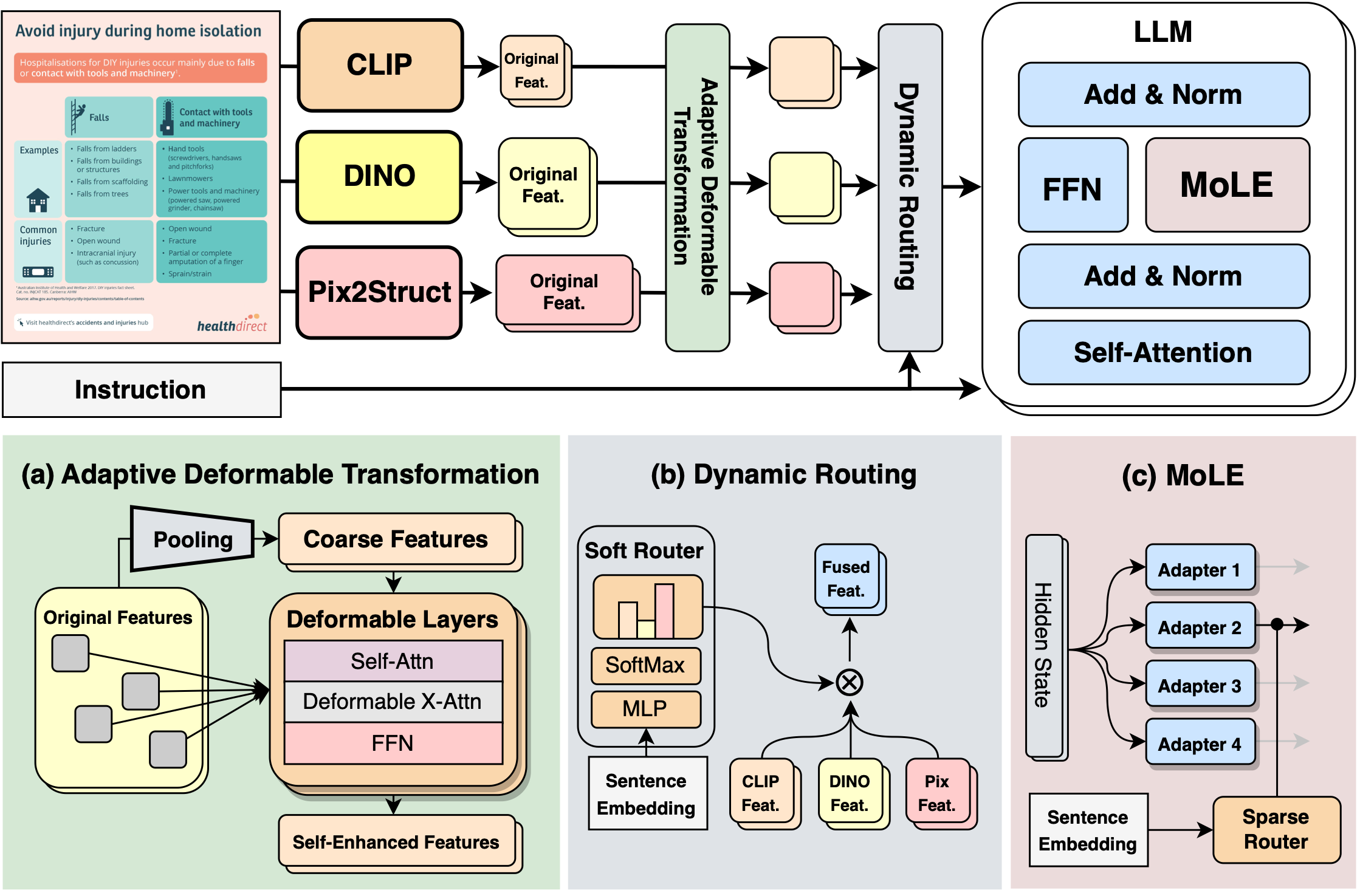
MoME: Mixture of Multimodal Experts for Generalist Multimodal Large Language Models
Leyang Shen, Gongwei Chen, Rui Shao, Weili Guan, Liqiang Nie
Advances in Neural Information Processing Systems 2024
In this work, we proposed a mixture of multimodal experts (MoME) framework to mitigate task interference and obtain a generalist MLLM.
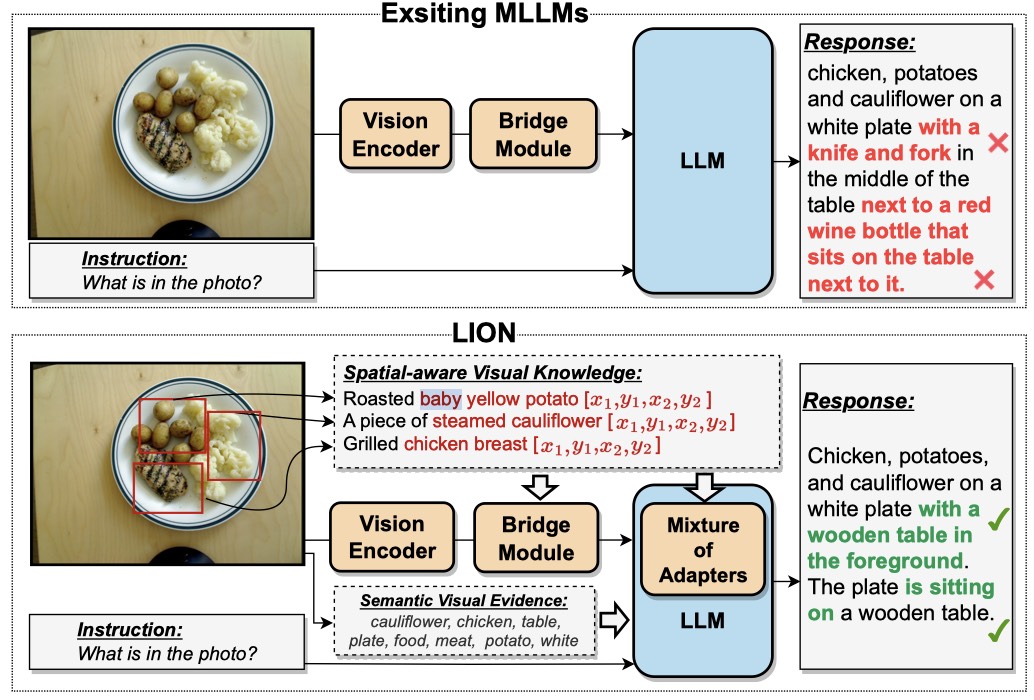
LION: Empowering Multimodal Large Language Model with Dual-Level Visual Knowledge
Gongwei Chen, Leyang Shen, Rui Shao, Xiang Deng, Liqiang Nie
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2024
In this work, we enhance MLLMs by integrating fine-grained spatial-aware visual knowledge and high-level semantic visual evidence, boosting capabilities and alleviating hallucinations.